Daten partitionieren statt archivieren (PNA)
Online-Verlauf und Verfügbarkeit bei gleichzeitiger Verbesserung der Antwortzeiten und Optimierung der Backup-Zeiten.
Eine moderne Art der Speicherung vergangener Daten ohne mühsame Archivierungs- und Wiederherstellungsprozesse.
Eines der größten Probleme, mit denen IT/CIO-Manager seit jeher konfrontiert sind, ist das Wachstum des Datenvolumens ihrer Systeme nach Jahren der Aktivität.
Die Nebeneffekte, die dieses Problem mit sich bringt, sind ein kontinuierlicher Rückgang der Systemleistung, ein kontinuierlicher Anstieg des Zeitaufwands für die Datenverwaltung und -sicherung sowie zusätzliche Kosten für die Hardware (Speicherplatz und Festplattenleistung).
Die Datenarchivierung ist die Lösung der alten Schule, aber wir bei Datatex sind der Meinung, dass die Methode der „Tabellenpartitionierung nach Daten“ eine bessere und effektivere Alternative ist, wenn man die Möglichkeiten der neuesten Technologie berücksichtigt. Die Datenarchivierung erfordert einen Archivierungsprozess auf zusätzlicher Infrastruktur und ein langwieriges, komplexes Wiederherstellungsprogramm, wenn auf diese Daten zugegriffen werden soll.
Tie Anwendung der „Tabellenpartitionierung“ führte in vielen Fällen zu folgenden Ergebnissen:
Verbesserung der Antwortzeiten
Verbesserung der Backup-Zeiten
Optimierung der Nutzung schneller, teurer Festplatten
Dieser Artikel zielt darauf ab, eine Technologie vorzustellen, die mit der Möglichkeit der Partitionierung der Tabellen die Verwendung von Datenarchivierung vermeiden kann. Es handelt sich um eine äußerst nützliche Technologie, da sie die Effizienz der Datenbank und folglich die Leistung des Systems verbessert.
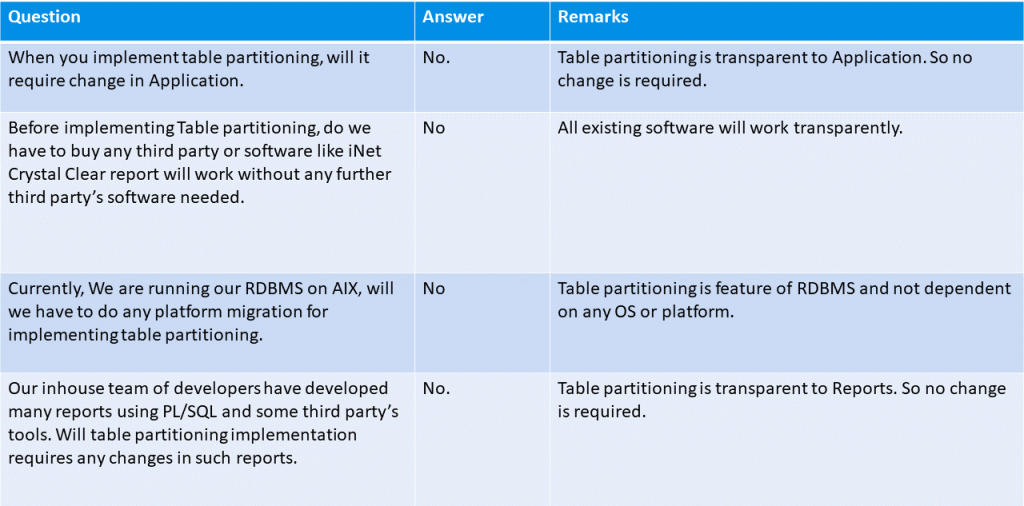
Die Partitionierung der Tabellen wird automatisch und transparent von der Datenbank selbst verwaltet, ohne dass zusätzliche Arbeit für die Anwendung oder das EDV-Personal, das das System verwaltet, entsteht. Sie besteht im Wesentlichen darin, eine Tabelle in mehrere Teile zu unterteilen, die getrennt verwaltet werden können.
Die Einteilung erfolgt nach logischen Kriterien, die wir im Folgenden erläutern werden. Normalerweise ist das am häufigsten verwendete Kriterium die Aufteilung nach Datum: Sie können eine Tabelle aufteilen, indem Sie in einem Teil die neuesten Daten und in den anderen die historischsten Daten aufbewahren, die, da sie viel seltener konsultiert werden, einen geringeren Einfluss auf das System haben.
Zusätzlich zur Definition der Partitionierungslogik wird auch die Positionierung auf den Systemfestplatten festgelegt, wobei beispielsweise die am meisten abgefragten Partitionen auf den leistungsstärksten Festplatten und die Partitionen mit historischen Daten auf den weniger leistungsfähigen Festplatten gehalten werden.
Auch die Backup-Phase kann von diesem Partitionierungssystem profitieren, da sie auf einzelnen Partitionen schneller durchgeführt werden kann. Die Technologie der Tabellenpartitionierung ist sehr nützlich, denn wenn eine Datenbank sehr groß ist, kann die Verwaltung archivierter Objekte sehr kostspielig sein und es können Probleme mit der Datenaufbewahrung und -wiederherstellung auftreten.
Diese Lösung löst diese Probleme, indem sie schnelle Reaktionszeiten bietet und es ermöglicht, Daten effektiv und auf eine anpassbare Weise zu organisieren, ohne relevante hohe Kosten zu verursachen und ohne ältere Daten in ein externes Archiv zu verschieben.
Es gibt mehrere Methoden zur Partitionierung einer Tabelle:

Auf diese Weise können dank einer effizienten Organisation der Festplatten die neuesten und am häufigsten verwendeten Daten auf den modernsten Festplatten gespeichert werden. Mit mehr Speicher werden die Kosten gesenkt, da die leistungsstärksten Festplatten für die neuesten Daten und die preiswerteren Festplatten für die weniger genutzten Daten verwendet werden. Dies führt zu einer schnelleren Reaktionszeit und niedrigeren Kosten. Darüber hinaus werden alle administrativen Datenbankaufgaben (z. B. Backups) optimiert, da sie auf einzelnen Partitionen durchgeführt werden können.
Ein weiterer Vorteil dieser Lösung gegenüber der externen Speicherung besteht darin, dass die Daten immer online bleiben und nicht auf ein externes Gerät verschoben werden, was für die Einheitlichkeit und den effizienten Abruf der Daten sehr wichtig ist. Alle Daten bleiben online und ändern nur ihre Organisation, wenn sie auf verschiedene Festplatten und Partitionen verschoben werden, die je nach Verwendungshäufigkeit unterschiedliche Leistungen bieten.
Diese Lösung bietet den besten Ausgleich zwischen den eingangs erwähnten Leistungs- und Zeitproblemen. Es handelt sich außerdem um eine betriebssystemunabhängige Lösung, die in Bezug auf das verwendete Verwaltungssystem transparent ist: Sie kann mit jeder Datenbank verwendet werden, ohne dass etwas an den bereits vorhandenen Einstellungen geändert werden muss.
Wir können die Vorteile der Tabellenpartitionierung wie folgt zusammenfassen:
Verbesserte Antwortzeiten und Abfrageleistung: Der DB2-Optimierer kennt die Partitionen, und wenn die Abfrage viele Zeilen durchsuchen muss, um eine Ergebnismenge zu erhalten, und das Prädikat (where-Klausel) definierte Bereiche verwendet, werden nur die Partitionen durchsucht, deren Zeilen die Abfrage erfüllen, anstatt die gesamte Tabelle zu durchsuchen. Dies wird als „Partitionseliminierung“ bezeichnet und kann die Abfragezeit erheblich verkürzen.
Verbesserte Backup-Zeiten: Verschiedene Wartungsaktivitäten wie die Reorganisation können auf einzelnen Partitionen durchgeführt werden, was im Vergleich zur Reorganisation der gesamten Tabelle sehr schnell ist. Das Arbeiten mit separaten Partitionen ist einfacher und schneller, da bestimmte Operationen für einzelne Bereiche ausgewählt werden können, was die Zeit reduziert. Geringere Backup-Zeiten bedeuten, dass die Systemressourcen für Benutzertransaktionen zur Verfügung stehen, anstatt sie auf dem Backup-Speicher zu speichern.
Optimierung der Nutzung der Festplatten: Die Daten bleiben online und müssen nicht auf externe Geräte verschoben werden. Es ermöglicht eine effiziente Nutzung des Speichers durch eine andere Organisation: Die Tabellenpartitionierung hilft uns, den Speicher besser zu nutzen. So können alte Partitionen, auf die weniger häufig zugegriffen wird, auf dem alten/langsamen Speicher platziert werden, während sich auf dem neueren und leistungsfähigeren Speicher die am häufigsten verwendeten und neuesten Informationen befinden.
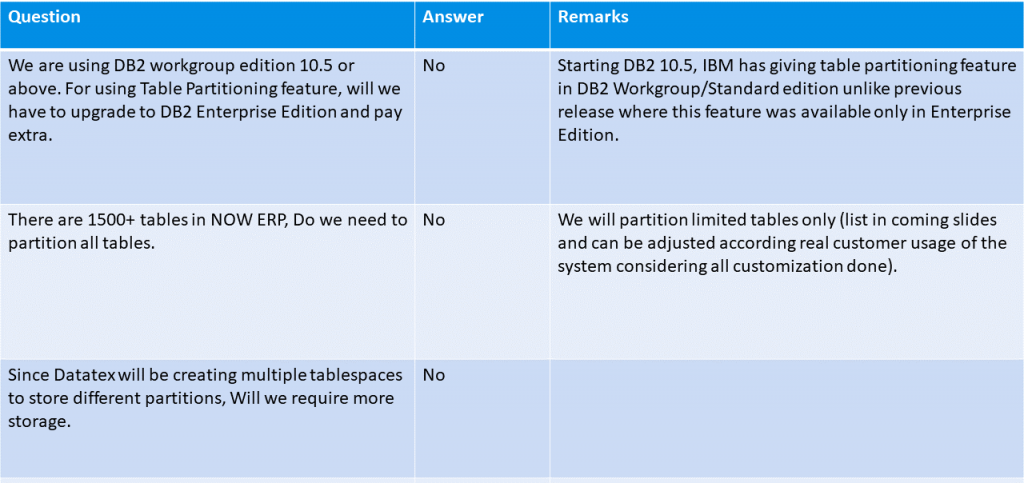
Hoher Grad an Flexibilität und Anpassungsfähigkeit: Tabellen können angepasst und partitioniert werden, um bestimmten Aufgaben gerecht zu werden. Es ist sehr einfach, die Partitionierungskriterien an die spezifischen Bedürfnisse anzupassen, die sich im Laufe der Zeit ändern können. Es ermöglicht sogar eine optimierte Roll-In- oder Roll-Out-Verarbeitung von Bereichen: Neue Partitionen können sehr schnell hinzugefügt und alte Partitionen bei Bedarf schnell wieder entfernt werden. Bei diesem Prozess werden Daten in eine neue Partition geladen oder eingefügt, bevor sie Teil der partitionierten Tabelle werden. Dieser Ladevorgang hat keine größeren Auswirkungen auf die Verwendung unserer Thementabelle als der Ladevorgang einer anderen unabhängigen Tabelle in der Datenbank. Sobald das Laden in die neue Partition abgeschlossen ist, wird der ATTACH-Befehl verwendet, um die neue Partition in die primäre Bereichspartitionstabelle zu integrieren.
Die besten Partitionskriterien werden je nach Tabelle und Datenverteilung ausgewählt: z.B. bei StockTransaction ist das geeignetste Kriterium das TRANSACTIONDATE oder bei anderen Tabellen kann es die CREATIONDATETIME sein und bei ADSTORAGE kann es die UNIQUEID sein, aber auch basierend auf realen Daten der ENTITYNAME.
Datatex hat Tests in einer realen Kundenumgebung durchgeführt, um die potenziellen Vorteile der Lösung in Bezug auf die Leistung der Endbenutzer zu messen. Die Ergebnisse zeigen, dass sich die Vorteile je nach den unterschiedlichen Daten und der unterschiedlichen Art der Nutzung des ERP-Systems ändern können. Alle Faktoren beeinflussen das Ergebnis und das Wichtigste ist, dass alle zusammenarbeiten, um zu verstehen, welches die besten Partitionen für die Leistung sind.
Geschrieben von Roberto Mazzola – Datatex CTO



