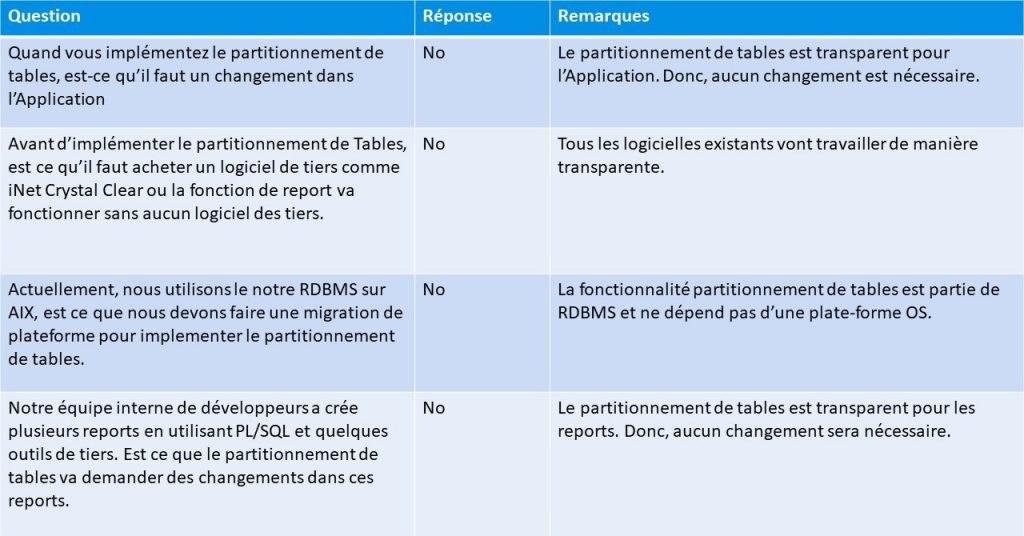
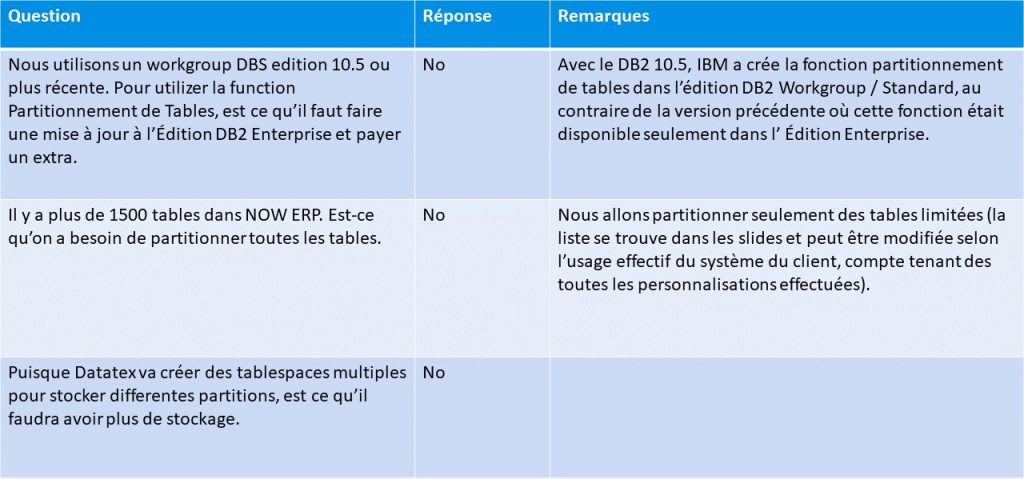
Partitionnement des données au lieu de l’archivage (PNA)
“Avoir une histoire disponible en ligne pendant qu’on améliore les temps de réponse et optimise les temps de sauvegarde. Une manière modern d’enregistrer les vieilles données sans besoin d’avoir d’enregistrements laborieux ou des processus de recouvrement. «
L’un des problèmes principaux que les responsables IT/CIO doivent toujours rencontrer est le grandissement en termes de « volume » des donnés dans leurs systèmes après des années d’activité.
Les effets indésirables crées par ce problèmes sont une diminution constante des performances du système, une augmentation continue des temps nécessaires à la gestion des donnée et du backup, coûts additionnels pour le hardware (espace du disque et performances du disque).
L’archivage des donnés est la solution plus commune, mais en Datatex nous croyons que la méthodologie « partitionnement de table » soit l’alternative plus efficace, compte tenant des possibilités fournies par les nouvelles technologies. L’archivage des données demande un processus d’archivage sur des infrastructures supplémentaires et des programmes de recouvrement laborieux et complexes au moment d’accéder à un donné spécifique.
L’application « partitionnement de tables » démontre en diffèrent cas les résultats suivants :
Temps de réponse améliorés
Temps de back up améliorés
Optimisation de l’usage des disques rapides et coûteux
Le but de cet article est l’introduction d’une technologie avec la possibilité de partitionner les tables, en évitant l’archivage des donnés. Il s’agit d’une technologie très utile puisqu’elle améliore l’efficience du database et par conséquence la performance du système.
Le partitionnement des tables est géré de manière automatique et transparente par le database même, sans créer du travail supplémentaire pour l’équipe EDP ou applicatif qui s’occupe du système.
Essentiellement, il consiste en diviser une table en plusieurs parties qui peuvent être gérées séparément. Cette division est faite sur la base des critères logiques que nous allons expliquer ci-dessous.
Normalement, le critère plus utilisé est la division par date : vous pouvez diviser une table en gardant dans une partie les données plus récents et dans les autres les donnés plus historiques qui, étant consultés moins fréquemment, ont un impact plus réduit sur le système. En plus de définir la logique de partitionnement, nous allons aussi définir le positionnement sur les disques du système, en gardant par exemples les partitions plus consultés sur les disques plus performant et les partitions avec les donnés historiques sur les disques moins efficients.
La phase de backup peut aussi bénéficier de ce Système de partitionnement parce qu’il peut être effectué sur des partitions singles de façon plus rapide. La technologie du partitionnement des tables est très utile parce que quand un database a une dimension très large, la gestion des objets peut être très coûteuse et des problèmes peuvent se poser concernant la retentions et le recouvrement des données.
Cette solution résout ces problèmes, en fournissant des temps de réponse rapides et en permettant d’organiser vos données efficacement, dans une manière personnalisable, sans des coûts très élevés et sans déplacer vos données dans un archive.
Cependant, il y a plusieurs méthodes de partitionner une table :

De cette manière, grâce à une organisation efficace des disques, il sera capable de loquer les données plus récents et plus utilisés dans les disques plus modernes. Avec plus de mémoire vous allez réduire les coûts, puisque vous employez les disques plus performants pour les données récents et les disques moins coûteux pour le stockage des donnés moins utilisés. Cela conduit à une réponse plus rapide et à des coûts inférieurs. En outre, toutes les fonctions administratives du database (comme les backups) sont optimisées parce qu’elles peuvent être effectuées sur des partitions individuelles.
Une force supplémentaire de cette solution, en comparaison avec des stockages externes, est que la donnée reste sur votre machine en tous cas et elle n’est pas déplacée sur des supports externes. Cela est très important afin d’assurer l’uniformité et une simple récupération des donnés. Tous vos donnés restent en ligne, seulement leur organisation change puisqu’ils sont déplacés dans différents disques qui offrent différentes performances en fonction de comment vous utilisez les données.
Cette solution offre définitivement le balancement meilleur afin de résoudre les problèmes liés à la performance et aux temps dont on a déjà parlé au débout. Il s’agit aussi d’une solution indépendante du système opératif et transparente, en ce qui concerne le système de gestion utilisé : vous pouvez l’utiliser avec n’importe quel database et le client ne doit pas changer rien de ses configurations préexistantes. En fait cette solution n’a aucun impact sur les activités et les décisions réalisées auparavant.
Nous pouvons récapituler les bénéfices du partitionnement des tables dans les points suivants :
Temps de réponse améliorés et performances d’interrogations : L’optimiseur DB2 est informé des partitions et si une interrogations nécessite de scanner plusieurs lignes afin d’obtenir votre série de résultat et votre prédicat (proposition) utilise les intervalles que vous avez défini, donc seulement les partitions qui ont des lignes qui satisfont votre interrogation seront recherchés, au lieux de fouiller le tableau en entier. Cela est appelé « élimination du partitionnement » et peut réduire énormément des temps de requête écoulés.
Temps de backup améliorés : Différentes activités de manutention comme la réorganisation peuvent être effectuées sur des partitionnements individuels qui peuvent être comparées très vitement afin de réorganiser la table en entier. Travailler avec des partitions séparées est plus facile et rapide puisque vous pouvez décider d’effectuer certaines opérations sur des espaces individuels, et cela va prendre moins de temps. Temps de backup réduits signifie que les ressources du système sont disponibles pour les transactions de l’usager au-delà de leur enregistrement sur la mémoire de sauvegarde.
Optimisation de l’utilisation des disques: vos données restent en ligne et vous n’avez pas besoin de les déplacer sur des dispositifs externes. Il permet un usage efficient du stockage à travers une organisation différente: le partitionnement des tables nous aide à mieux utiliser notre mémorisation ; en fait les partitions plus vieilles qui sont consultées moins fréquemment, peuvent être placées sur des disques vieux / lents tandis que dans les mémoires plus nouvelles et performantes il y a les informations plus utilisées et récentes.
Haut niveau de flexibilité et personnalisation: vous pouvez customiser les tables et les partitions pour les adapter à vos taches. Il est très simple d’ajuster les critères de partitionnement à vos exigences, qui peuvent changer au cours du temps. En effet, il permet d’optimiser les processus roll-in et roll-out des gammes : nouvelles partitions peuvent très vitement être jointe, et les partitions plus vieilles peuvent être détachées très aisément si nécessaire. Pendant ce processus vous chargez ou insérez des données dans une partition nouvelle avant de la rendre partie de la table partitionnée. Ce processus de chargement n’a plus d’effet sur l’usage de notre table sujet que le chargement de toute autre table indépendant dans le database. Après avoir finis de charger la nouvelle partition, vous utilisez le command ANNEXER afin d’intégrer la nouvelle partition dans la Gamme de Table Partitionnement primaire.
En fonction de chaque table et distribution des donnés, nous allons sélectionner les critères de partition meilleures : Par exemple sur les Transactions Boursières le critère plus efficace est le TRANSACTIONDATE ou bien une autre table appelée CREATIONDATETIME et sur le ADSTORAGE peut être le UNIQUEID mais aussi basé sur des donnés réels par ENTITYNAME.
Datatex a réalisé des tests sur des environnements réels des consommateurs afin de mesurer les bénéfices potentiels de la solution en termes de performance end-user. Les résultats démontrent que les bénéfices peuvent changer sur la base des donnés différents et des différentes modalités d’utiliser le système PRE.
Tous les facteurs influencent le résultat finale et l’essentiel est de travailler tous ensemble afin de comprendre quelles sont les meilleures partitions pur la performance.