Arşivleme Yerine Veri Bölümleme (PNA)
Yanıt sürelerini iyileştirirken ve yedekleme sürelerini optimize ederken geçmişin çevrimiçi ve kullanılabilir olması.
Sıkıcı arşivleme ve kurtarma süreçlerine gerek kalmadan geçmiş verileri depolamanın modern bir yolu.
BT/CIO yöneticilerinin her zaman karşılaştığı en büyük sorunlardan biri, yıllar süren faaliyetlerin ardından sistemlerindeki verilerin “hacim” açısından büyümesidir.
Bu sorunun yarattığı yan etkiler, sistem performansının sürekli olarak düşmesi, veri yönetimi ve yedekleme için gereken sürenin sürekli olarak artması, donanım için ek maliyet (disk alanı ve disk performansı).
Veri arşivleme eski bir çözümdür, ancak Datatex’te “veriye göre tablo bölümleme” metodolojisinin en son teknolojinin sağladığı olanaklar göz önüne alındığında daha iyi ve daha etkili bir alternatif olduğuna inanıyoruz. Veri arşivleme, ek bir altyapı üzerinde arşivleme işlemi ve bu verilere erişilmesi gerektiğinde sıkıcı ve karmaşık kurtarma programları gerektirir.
“Tablo bölümleme” uygulaması birçok durumda aşağıdaki sonuçları göstermiştir:
Yanıt sürelerini iyileştirin
Yedekleme sürelerini iyileştirin
Hızlı ve pahalı disklerin kullanımını optimize edin
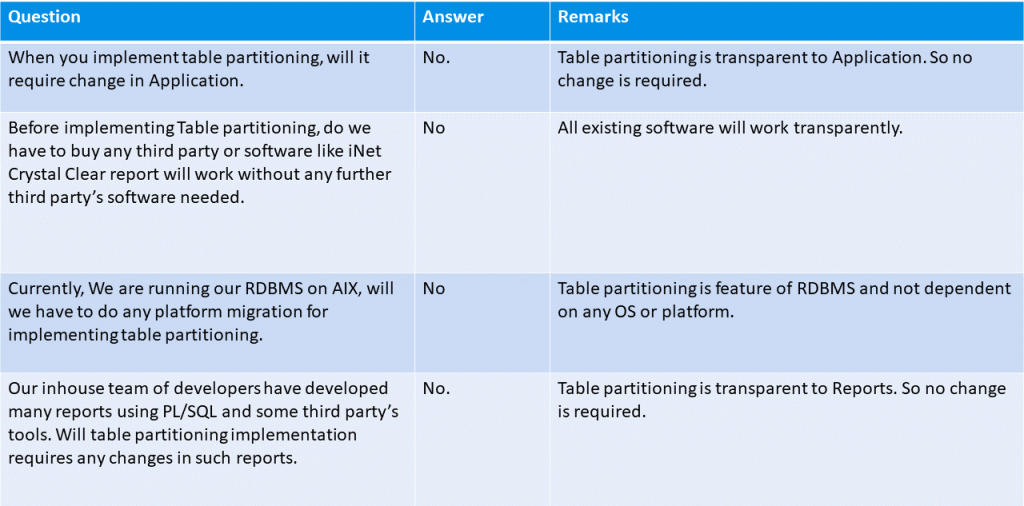
Bu makale, tabloları bölümleme imkanı ile veri arşivleme kullanımından kaçınabileceğimiz bir teknolojiyi tanıtmayı amaçlamaktadır.
Veritabanının verimliliğini ve dolayısıyla sistemin performansını artırdığı için son derece faydalı bir teknolojidir. Tabloların bölümlendirilmesi, uygulama veya sistemi yöneten EDP personeli için ek iş yaratmadan, veritabanının kendisi tarafından otomatik ve şeffaf bir şekilde yönetilir. Temel olarak, bir tablonun ayrı ayrı yönetilebilen birkaç parçaya bölünmesinden oluşur.
Bölünme, aşağıda açıklayacağımız mantıksal kriterlere göre yapılır. Normalde en çok kullanılan kriter tarihe göre bölmedir: bir tabloyu bir bölümde en yeni verileri, diğer bölümlerde ise çok daha az sıklıkla başvurulan ve sistem üzerinde daha az etkisi olan en geçmiş verileri tutarak bölebilirsiniz.
Bölümleme mantığını tanımlamanın yanı sıra, sistem diskleri üzerindeki konumlandırmayı da tanımlayacağız, örneğin en çok başvurulan bölümleri en performanslı disklerde ve geçmiş verileri içeren bölümleri daha az verimli disklerde tutacağız.
Yedekleme aşaması da bu bölümleme sisteminden faydalanabilir çünkü tek bölümler üzerinde daha hızlı bir şekilde yapılabilir. Tablo bölümleme teknolojisi çok kullanışlıdır çünkü bir veritabanı çok büyük olduğunda, arşivlenmiş nesnelerin yönetimi çok pahalı olabilir ve veri saklama ve kurtarma ile ilgili sorunlar ortaya çıkabilir.
Bu çözüm, hızlı yanıt süreleri sağlayarak ve verileri etkin bir şekilde, özelleştirilebilir bir şekilde, ilgili yüksek maliyetlerden kaçınarak ve eski verileri harici bir arşive taşımadan düzenlemeye izin vererek bu sorunları çözer.
Bir tabloyu bölümlendirmenin birden fazla yöntemi vardır:

Bu şekilde, disklerin verimli bir şekilde organize edilmesi sayesinde, en yeni ve en çok kullanılan veriler en modern disklerde bulunabilir. En yeni veriler için en performanslı diskler ve daha az kullanılan veri depolama için daha ucuz diskler kullanıldığından daha fazla bellek ile maliyetler azalacaktır. Bu da daha yüksek yanıt hızı ve daha düşük maliyet sağlar. Ayrıca, tüm yönetimsel veritabanı görevleri (yedeklemeler gibi) ayrı bölümler üzerinde gerçekleştirilebildiği için optimize edilmiştir.
Bu çözümün harici depolamaya kıyasla bir diğer güçlü yanı, verilerin her zaman çevrimiçi kalması ve herhangi bir harici cihaza taşınmamasıdır; bu, verilerin bütünlüğünü ve verimli bir şekilde geri alınmasını sağlamak için çok önemlidir. Tüm veriler çevrimiçi kalır, yalnızca ne sıklıkta kullanıldığına bağlı olarak farklı performanslar sunan farklı disklere ve bölümlere taşındıkça organizasyonunu değiştirir.
Bu çözüm, başlangıçta bahsedilen performans ve zaman sorunlarını çözen en iyi dengeyi sunar. Aynı zamanda işletim sisteminden bağımsız bir çözümdür ve kullanılan yönetim sistemi açısından şeffaftır: önceden var olan ayarların hiçbirini değiştirmeye gerek kalmadan herhangi bir veritabanıyla kullanılabilir, bu çözüm daha önce gerçekleştirilen tüm faaliyetleri ve alınan kararları etkilemez.
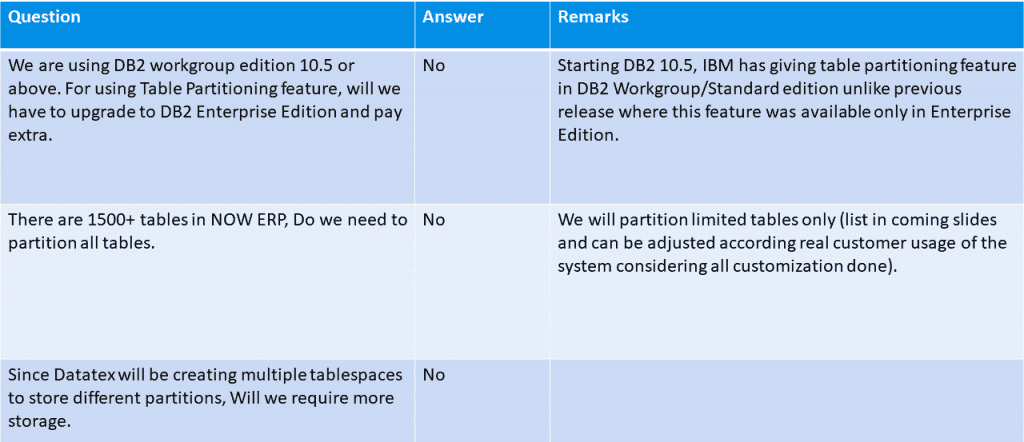
Tablo bölümlemenin faydalarını aşağıdaki gibi özetleyebiliriz:
İyileştirilmiş yanıt süreleri ve sorgu performansı: DB2 optimizer bölümlerin farkındadır ve sorgunun bir sonuç kümesi elde etmek için birçok satırı taraması gerekiyorsa ve yüklem (where cümlesi) tanımlanmış aralıkları kullanıyorsa, tüm tabloyu aramak yerine yalnızca sorguyu karşılayan satırlara sahip bölümler aranacaktır. Buna “bölüm eleme” denir ve sorguda geçen süreyi büyük ölçüde azaltabilir.
Geliştirilmiş yedekleme süreleri: Yeniden düzenleme gibi çeşitli bakım faaliyetleri, tüm tablonun yeniden düzenlenmesine kıyasla çok hızlı olacak şekilde tek tek bölümler üzerinde yapılabilir. Ayrı bölümlerle çalışmak, belirli işlemler ayrı alanlarda seçilebildiğinden daha kolay ve daha hızlıdır ve bu da zamanı azaltacaktır. Yedekleme sürelerinin kısalması, sistem kaynaklarının yedekleme deposuna kaydedilmesi dışında kullanıcı işlemleri için kullanılabilir olduğu anlamına gelir.
Disklerin kullanımının optimizasyonu: Veriler çevrimiçi kalır ve harici cihazlara taşınmasına gerek yoktur. Farklı bir organizasyon aracılığıyla depolamanın verimli bir şekilde kullanılmasını sağlar: tablo bölümleme, depolamayı daha iyi kullanmamıza yardımcı olur, aslında daha az sıklıkla erişilen eski bölümler eski / yavaş depolamaya yerleştirilebilirken, daha yeni ve daha performanslı depolamada en çok kullanılan ve en son bilgiler bulunur.
Yüksek derecede esneklik ve özelleştirme: Tablolar belirli görevlere uyacak şekilde özelleştirilebilir ve bölümlendirilebilir. Bölümleme kriterlerini zaman içinde değişebilen özel ihtiyaçlara göre ayarlamak çok kolaydır. Aslında, aralıkların optimize edilmiş içeri veya dışarı alma işlemine izin verir: yeni bölümler çok hızlı bir şekilde eklenebilir ve eski bölümler gerektiğinde hızlı bir şekilde ayrılabilir. Bu işlemde, bölümlenmiş tablonun bir parçası haline getirmeden önce yeni bir bölüme veri yüklenir veya eklenir. Bu yükleme işleminin konu tablomuzun kullanımı üzerinde, veritabanındaki diğer bağımsız tabloların yüklenmesinden daha fazla etkisi yoktur. Yeni bölüme yükleme tamamlandıktan sonra, yeni bölümü birincil Aralık Bölümleme Tablosuna entegre etmek için ATTACH komutu kullanılır.
Her tabloya ve veri dağılımına göre en iyi bölümleme kriteri seçilecektir: örneğin StockTransaction’da en uygun kriter TRANSACTIONDATE’dir veya diğer tablolarda CREATIONDATETIME olabilir ve ADSTORAGE’da UNIQUEID olabilir, ancak aynı zamanda ENTITYNAME ile gerçek verilere dayanabilir.
Datatex, çözümün son kullanıcı performansı açısından potansiyel faydalarını ölçmek için gerçek müşteri ortamında testler gerçekleştirmiştir ve sonuçlar, faydaların farklı verilere ve ERP sisteminin farklı kullanım biçimlerine göre değişebileceğini göstermektedir. Tüm faktörler sonucu etkiler ve en önemli şey, performans için en iyi bölümlerin hangileri olduğunu anlamak için hep birlikte çalışmaktır.
Roberto Mazzola – Datatex CTO tarafından yazıldı


