Partizione dei dati anziché archiviazione (PNA)
“Avere la cronologia online e disponibile, migliorando i tempi di risposta e ottimizzando i tempi di backup.
Un modo moderno di conservare i vecchi dati senza la necessità di tediosi processi di archiviazione e recupero”.
Uno dei maggiori problemi che i responsabili IT/CIO hanno sempre dovuto affrontare è l’aumento di “volume” dei dati del loro sistema dopo anni di attività.
Gli effetti creati da questo problema sono una continua diminuzione delle prestazioni del sistema, un continuo aumento del tempo necessario per l’amministrazione e il backup dei dati e un costo aggiuntivo per l’hardware (spazio su disco e prestazioni del disco).
L’archiviazione dei dati è la soluzione della vecchia scuola, ma in Datatex crediamo che la metodologia del “table partitioning by data” sia un’alternativa migliore e più efficace, considerando le possibilità offerte dalla tecnologia più recente. L’archiviazione dei dati richiede un processo di archiviazione su infrastrutture aggiuntive e un noioso e complesso programma di recupero quando è necessario accedere a questi dati.
L’applicazione del “table partitioning” ha mostrato in molti casi i seguenti risultati:
Migliori tempi di risposta
Migliori tempi di backup
L’utilizzo ottimizzato di dischi veloci e costosi.
Questo articolo vuole quindi introdurre una tecnologia con la possibilità di partizionare le tabelle evitando l’uso dell’archiviazione dati. Si tratta di una tecnologia estremamente utile in quanto migliora l’efficienza del database e di conseguenza le prestazioni del sistema.
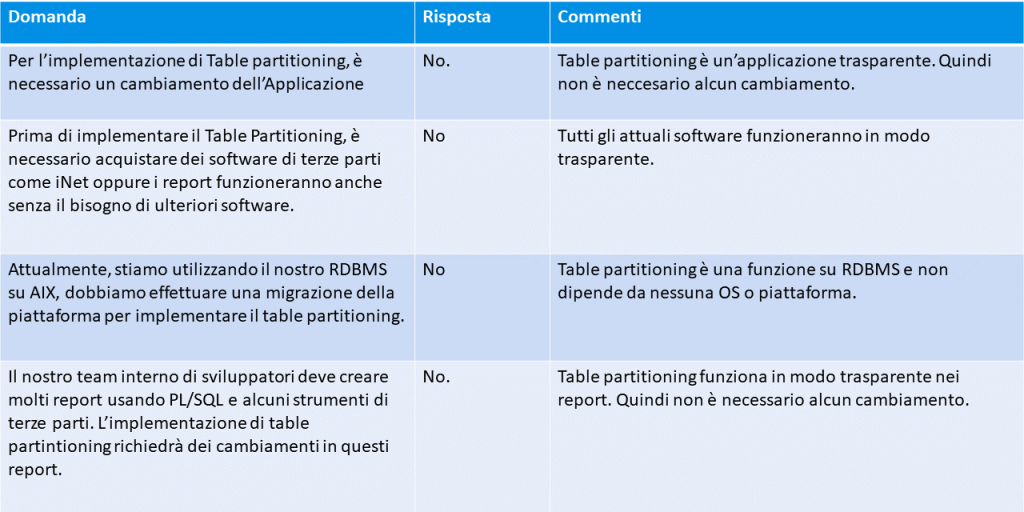
Il partizionamento delle tabelle è gestito automaticamente e in modo trasparente dal database stesso, senza creare lavoro aggiuntivo per l’applicazione o per il personale EDP che gestisce il sistema. Fondamentalmente, consiste nel dividere una tabella in più parti che possono essere gestite separatamente. La divisione viene effettuata secondo criteri logici che spiegheremo di seguito.
Normalmente il criterio più utilizzato è la divisione per data: si può suddividere una tabella mantenendo in una parte i dati più recenti e nelle altre i più storici, che, essendo consultati molto meno frequentemente, hanno un impatto minore sul sistema.
Oltre a definire la logica di partizionamento, si definirà anche il posizionamento sui dischi del sistema, mantenendo ad esempio le partizioni più consultate sui dischi più performanti e le partizioni con dati storici sui dischi meno efficienti. Anche la fase di backup può beneficiare di questo sistema di partizionamento perché può essere effettuata su singole partizioni in modo più rapido.
La tecnologia del partizionamento delle tabelle è molto utile perché quando un database ha una dimensione molto grande, la gestione degli oggetti può essere molto costosa e possono sorgere problemi di conservazione e recupero dei dati. Questa soluzione risolve questi problemi, fornendo tempi di risposta rapidi e permettendo di organizzare i dati in modo efficace, personalizzabile, senza costi elevati e senza spostare i dati in un archivio.
Esistono diversi metodi di partizionamento di una tabella:

In questo modo, grazie ad un’efficiente organizzazione dei dischi, sarà possibile localizzare i dati più recenti e più utilizzati nei dischi più moderni. Con più memoria si riducono i costi, in quanto si utilizzano i dischi più performanti per i dati recenti e i dischi meno costosi per la memorizzazione dei dati meno utilizzati. Questo porta ad una maggiore velocità di risposta e a costi inferiori.
Inoltre, tutti i compiti amministrativi del database (come i backup) sono ottimizzati perché possono essere eseguiti su singole partizioni. Un ulteriore punto di forza di questa soluzione, rispetto alla memorizzazione esterna, è che i dati rimangono comunque sulla macchina e non vengono spostati su alcun dispositivo esterno; questo è molto importante per garantire l’uniformità e la facilità di recupero dei dati. Tutti i vostri dati rimangono online, cambiano solo la loro organizzazione man mano che vengono spostati su dischi diversi che offrono prestazioni diverse a seconda di come si utilizzano i dati. Questa soluzione offre sicuramente il miglior equilibrio per risolvere i problemi di prestazioni e di tempo di cui abbiamo parlato all’inizio.
È anche una soluzione indipendente dal sistema operativo e trasparente rispetto al sistema di gestione utilizzato: si può utilizzare con qualsiasi database e il cliente non ha bisogno di modificare nulla delle sue impostazioni preesistenti, poiché questa soluzione non incide su tutte le attività svolte e le decisioni prese in precedenza.
Possiamo quindi riassumere i vantaggi della suddivisione delle tabelle nei seguenti punti:
Miglioramento dei tempi di risposta e delle prestazioni della query: L’ottimizzatore DB2 è consapevole delle partizioni e se la vostra query deve scansionare molte righe per ottenere il vostro set di risultati e il vostro predicato (la clausola) utilizza intervalli che avete definito, allora solo le partizioni che hanno righe che soddisfano la vostra query verranno cercate invece di cercare l’intera tabella. Questo si chiama “eliminazione delle partizioni” e può ridurre notevolmente i tempi di interrogazione.
Tempi di backup migliorati: Varie attività di manutenzione come la riorganizzazione possono essere fatte su singole partizioni che saranno molto veloci rispetto alla riorganizzazione dell’intera tabella. Lavorare con partizioni separate è più facile e veloce in quanto si può scegliere di fare determinate operazioni su singoli spazi, e questo richiederà molto meno tempo. La riduzione dei tempi di backup significa che le risorse di sistema sono disponibili per le transazioni degli utenti, oltre che per il salvataggio su memoria di backup.
Ottimizzazione dell’utilizzo dei dischi: I vostri dati rimangono online e non è necessario spostarli su dispositivi esterni. Permette un uso efficiente dello storage attraverso un’organizzazione diversa: il partizionamento delle tabelle ci aiuta a utilizzare meglio il nostro storage, infatti le vecchie partizioni a cui si accede meno frequentemente, possono essere posizionate su storage vecchio/basso mentre nello storage più recente e performante ci sono le informazioni più utilizzate e recenti.
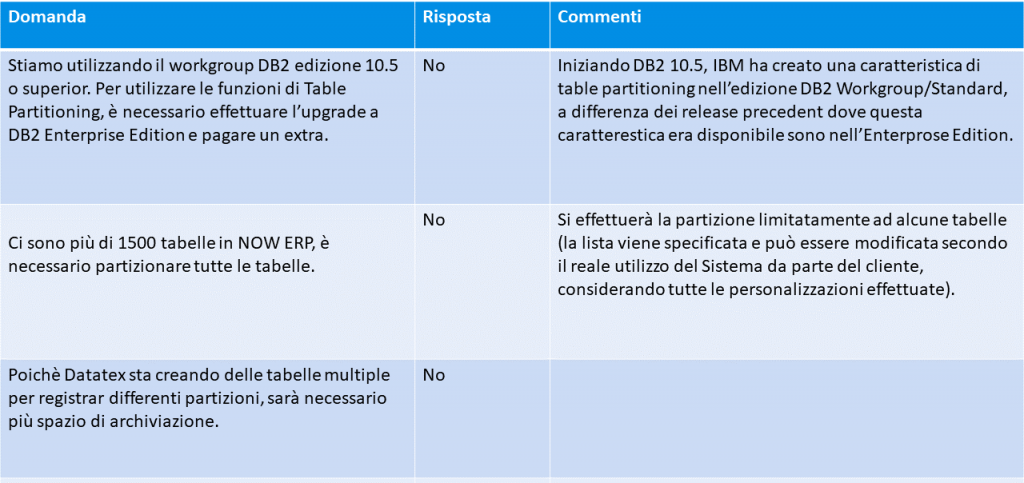
Elevata flessibilità e personalizzazione: è possibile personalizzare le tabelle e le partizioni in base alle proprie esigenze. È molto facile adattare i criteri di partizionamento alle proprie esigenze, che possono cambiare nel tempo. Infatti, permette un’elaborazione ottimizzata del roll-in o roll-out delle gamme: le nuove partizioni possono essere attaccate molto rapidamente, e le vecchie partizioni possono essere rapidamente staccate a seconda delle necessità. In questo processo si caricano o si inseriscono dati in una nuova partizione prima di renderla parte della tabella di partizionamento. Questo processo di caricamento non ha più effetto sull’uso della nostra tabella dei soggetti che il caricamento di qualsiasi altra tabella indipendente nel database. Una volta terminato il caricamento della nuova partizione si usa il comando ATTACH per integrare la nuova partizione nella tabella delle partizioni primaria.
In base a ciascuna tabella e alla distribuzione dei dati, selezioneremo i migliori criteri di partizione: Ad esempio su StockTransaction il criterio più adatto è la TRANSACTIONDATE o su un’altra tabella può essere la CREATIONDATETIME e su ADSTORAGE può essere l’UNIQUEID ma anche basato su dati reali per ENTITYNAME.
Datatex ha condotto test sull’ambiente reale del cliente per misurare i potenziali benefici della soluzione in termini di performance dell’utente finale e i risultati mostrano che i benefici possono cambiare in base ai diversi dati e alle diverse modalità di utilizzo del sistema ERP.
Tutti i fattori influenzano il risultato finale e la cosa più importante è lavorare tutti insieme per capire quali sono le migliori partizioni per le singole prestazioni.