Partición de datos en lugar de archivo (PNA)
«Tener el historial en línea y disponible mientras se mejoran los tiempos de respuesta y se optimizan los backups.
Una forma moderna de almacenar datos históricos sin necesidad de tediosos procesos de archivoy recuperación».
Uno de los mayores problemas a los que se han enfrentado siempre los directores de IT/CIO es el crecimiento en términos del volumen de los datos en su sistema después de años de actividad.
Los efectos secundarios creados por este problema son una disminución del rendimiento del sistema, un aumento del tiempo necesario para la administración de los datos y la generación de copias de respaldo o backups y un costo adicional para el hardware (espacio y rendimiento del disco).
La solución tradicional ha sido siempre el archivo de datos, pero en Datatex creemos que la metodología de «partición de tablas de datos» es una alternativa mejor y más efectiva considerando las posibilidades que ofrecen las nuevas tecnologías. El archivo de datos históricos requiere un proceso de almacenamiento en una infraestructura adicional y un tedioso y complejo programa de recuperación cuando se requiere acceder a estos datos.
La aplicación de la partición de tablas mostró en muchos casos los siguientes resultados:
Mejorar los tiempos de respuesta
Mejorar los tiempos de backup
Optimizar el uso de discos rápidos y costosos
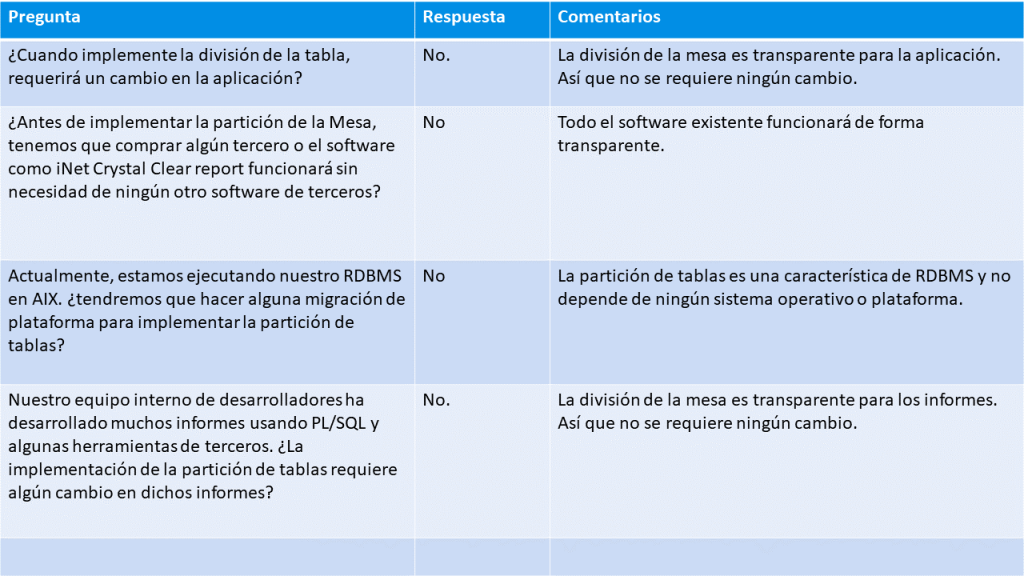
Este artículo pretende introducir la tecnología de partición de tablas. Se trata de una tecnología extremadamente útil ya que mejora la eficiencia de la base de datos y, por consiguiente, el rendimiento del sistema. La partición de tablas se gestiona de forma automática y transparente por la propia base de datos, sin crear trabajo adicional para la aplicación o para el personal de TI que gestiona el sistema. Básicamente, consiste en dividir un cuadro (tablespace) en varias partes que pueden ser gestionadas por separado.
La división se hace según criterios lógicos que explicaremos más adelante. Normalmente el criterio más utilizado es la división por fechas: se puede dividir un cuadro conservando en una parte los datos más recientes y en las otras los más antiguos, que al ser consultados con mucha menos frecuencia, tienen un impacto menor en el sistema.
Además de definir la lógica de la partición, también definiremos la posición en los discos del sistema, manteniendo por ejemplo las particiones más consultadas en los discos de mayor rendimiento y las particiones con datos históricos en los discos de menor performance. La fase de backup también puede beneficiarse de este sistema de partición porque puede hacerse en particiones individuales de manera más rápida.
La tecnología de la partición de tablas es muy útil porque cuando una base de datos tiene un tamaño muy grande, la gestión de los objetos puede ser muy costosa y pueden surgir problemas con la retención y recuperación de los datos.
Esta solución resuelve estos problemas, proporcionando tiempos de respuesta rápidos y permitiéndole organizar sus datos de manera eficaz, de forma personalizable, sin altos costos y sin mover parte de los datos a un archivo.

De esta manera, gracias a una eficiente organización de los discos, podrá colocar los datos más recientes y utilizados en los discos más modernos. Con mayor memoria se reducen los costos, ya que utiliza los discos de mayor rendimiento para los datos recientes y los discos de menor rendimiento pero más económicos para el almacenamiento de los datos menos utilizados. Esto conduce a una mayor velocidad de respuesta y a menores costos. Además, todas las tareas administrativas de la base de datos (como las de backup) se optimizan porque pueden realizarse en particiones individuales.
Otro punto fuerte de esta solución, en comparación con el almacenamiento externo, es que los datos permanecen en la máquina de todos modos y no se trasladan a ningún dispositivo externo; esto es muy importante para garantizar la uniformidad y la fácil recuperación de los datos.
Todos sus datos permanecen en línea, sólo cambia su organización al ser movidos a diferentes discos que ofrecen diferentes rendimientos dependiendo de cómo se utilicen los datos. Esta solución definitivamente ofrece el mejor equilibrio para resolver los problemas de rendimiento y tiempo de los que hablamos al principio.
También es una solución independiente del sistema operativo y transparente con respecto al sistema de gestión utilizado: puede utilizarse con cualquier base de datos y el cliente no necesita cambiar nada de su configuración preexistente, esta solución no afecta las actividades realizadas y decisiones tomadas anteriormente.
A continuación, podemos resumir las ventajas de la partición de tablas en los siguientes puntos:
Mejora de los tiempos de respuesta y del rendimiento de las consultas: El optimizador DB2 conoce las particiones y si su consulta necesita escanear muchas filas para obtener el conjunto de resultados y su predicado (cláusula where) utiliza los rangos que usted definió, entonces sólo se buscarán las particiones que tengan las filas que satisfacen su consulta en lugar de buscar en toda la tabla. Esto se llama «eliminación de particiones» y puede reducir enormemente los tiempos de consulta.
Mejora de los tiempos de backup: Se pueden realizar varias actividades de mantenimiento como la reorganización de las particiones individuales, lo que será muy rápido comparado con la reorganización de toda la tabla. Trabajar con particiones separadas es más fácil y rápido ya que se puede elegir hacer ciertas operaciones en espacios individuales, y esto llevará mucho menos tiempo. La reducción de los tiempos de backup significa que los recursos del sistema están disponibles para las transacciones de los usuarios, aparte de guardarlos en el almacenamiento de backup.
Optimización del uso de los discos: Los datos permanecen en línea y no es necesario trasladarlos a dispositivos externos. Permite un uso eficiente del almacenamiento a través de una organización diferente: la partición de las tablas nos ayuda a utilizar mejor nuestro espacio de almacenamiento, de hecho las particiones antiguas que se acceden con menos frecuencia, se pueden colocar en un almacenamiento antiguo/lento mientras que en el almacenamiento más nuevo y de mayor rendimiento se encuentra la información más utilizada y reciente.
Alto grado de flexibilidad y personalización: se pueden personalizar las tablas y las particiones para que se ajusten a sus tareas. Es muy fácil ajustar los criterios de partición a sus necesidades, que pueden cambiar con el tiempo. De hecho, permite un procesamiento optimizado de los rangos: las nuevas particiones se pueden conectar muy rápidamente, y las particiones antiguas se pueden separar rápidamente según sea necesario. En este proceso se cargan o insertan datos en una nueva partición antes de hacerla parte de la tabla de particiones. Este proceso de carga no tiene más efecto en el uso de nuestra tabla de particiones que la carga de cualquier otra tabla independiente en la base de datos. Una vez que se termine de cargar la nueva partición, con el uso de un comando (ATTACH) se integra la nueva partición en la Tabla de Particiones de Rango primaria.
De acuerdo con cada tabla y con la distribución de datos, seleccionaremos el mejor criterio de partición: Por ejemplo, en una tabla de transacciones de inventario el criterio más adecuado es la fecha de la transacción. En otra tabla puede ser la fecha de creación del registro y el código único (UNIQUEID) pero también basado en datos reales por el nombre de la entidad (ENTITYNAME).
Datatex ha realizado pruebas en el entorno real del cliente para medir los beneficios potenciales de la solución en términos de rendimiento del usuario final y los resultados muestran que los beneficios pueden cambiar de acuerdo con los diferentes datos y las diferentes formas de utilizar el sistema NOW. Todos los factores influyen en el resultado final y lo más importante es un trabajo de equipo entre Datatex y el cliente para comprender cuáles son las mejores particiones para maximizar el rendimiento.

Escrito por Roberto Mazzola – CTO Datatex



