Partição de dados em vez de arquivamento (PNA)
Ter o histórico em linha e disponível, melhorando os tempos de resposta e optimizando os tempos de cópia de segurança.
Uma forma moderna de armazenar dados passados sem a necessidade de processos aborrecidos de arquivo e recuperação.
Um dos maiores problemas que os gestores de TI/CIO sempre enfrentaram foi o crescimento em termos de “volume” de dados do seu sistema após anos de atividade.
Os efeitos secundários criados por este problema são uma diminuição contínua do desempenho do sistema, um aumento contínuo do tempo necessário para a administração dos dados e para a realização de cópias de segurança, custos adicionais para o hardware (espaço em disco e desempenho do disco).
O arquivamento de dados é a solução da velha guarda, mas na Datatex acreditamos que a metodologia de “particionamento de tabelas por dados” é uma alternativa melhor e mais eficaz, considerando as possibilidades oferecidas pela tecnologia mais recente. O arquivamento de dados requer um processo de arquivamento em infra-estruturas adicionais e programas de recuperação complexos e fastidiosos quando é necessário aceder a estes dados.
A aplicação do “particionamento de tabelas” mostrou, em muitos casos, os seguintes resultados:
Melhorar os tempos de resposta
Melhorar os tempos de cópia de segurança
Otimizar a utilização de discos rápidos e dispendiosos
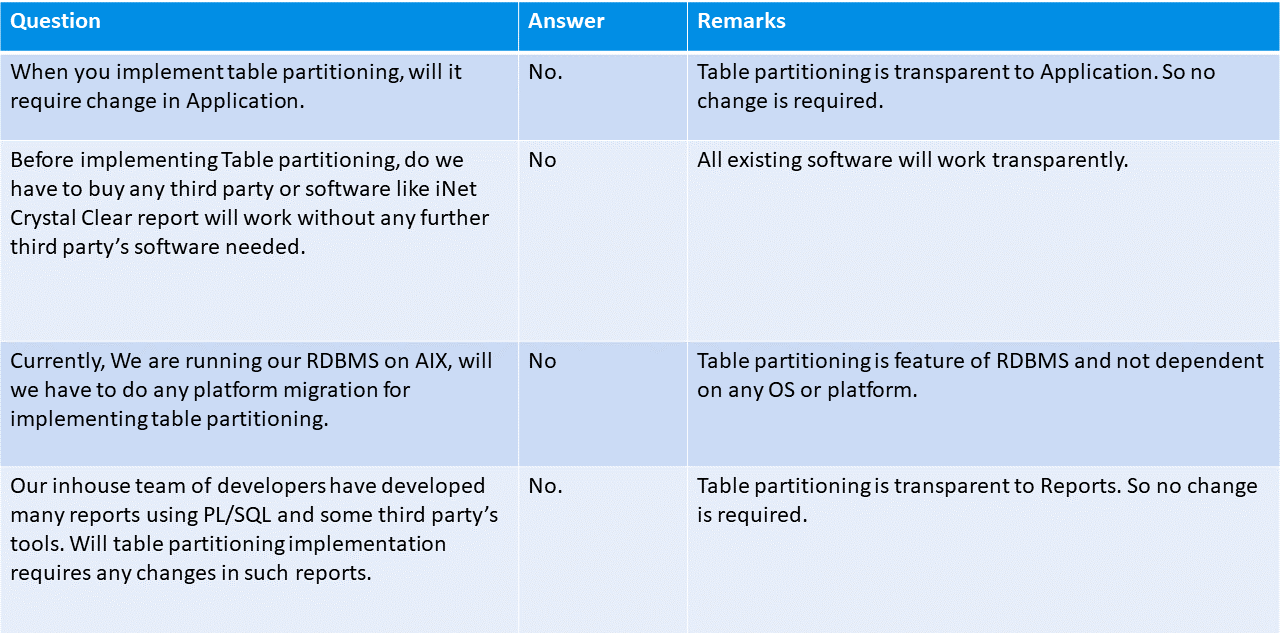
Este artigo tem como objetivo apresentar uma tecnologia que, com a possibilidade de particionar as tabelas, permite evitar a utilização do arquivo de dados. É uma tecnologia extremamente útil pois melhora a eficiência da base de dados e consequentemente o desempenho do sistema. O particionamento de tabelas é gerido de forma automática e transparente pela própria base de dados, sem criar trabalho adicional para a aplicação ou para a equipa da EDP que gere o sistema. Basicamente, consiste na divisão de uma tabela em várias partes que podem ser geridas separadamente.
A divisão é feita de acordo com critérios lógicos que explicaremos a seguir. Normalmente o critério mais utilizado é a divisão por data: pode-se dividir uma tabela mantendo numa parte os dados mais recentes e nas outras os mais históricos, que, sendo consultados com muito menos frequência, têm um menor impacto no sistema.
Para além de definirmos a lógica de particionamento, definiremos também o posicionamento nos discos do sistema, mantendo, por exemplo, as partições mais consultadas nos discos com melhor desempenho e as partições com dados históricos nos discos menos eficientes.
A fase de cópia de segurança também pode beneficiar deste sistema de particionamento porque pode ser efectuada em partições individuais de uma forma mais rápida. A tecnologia de particionamento de tabelas é muito útil porque quando uma base de dados é muito grande, a gestão de objectos arquivados pode ser muito dispendiosa e podem surgir problemas com a retenção e recuperação de dados.
Esta solução resolve estes problemas, proporcionando tempos de resposta rápidos e permitindo organizar os dados de forma eficaz e personalizável, evitando custos elevados relevantes e sem deslocar os dados mais antigos para um arquivo externo.
Existem vários métodos de particionamento de uma tabela:

Desta forma, graças a uma organização eficiente dos discos, os dados mais recentes e mais utilizados podem ser localizados nos discos mais modernos. Com mais memória, os custos serão reduzidos, uma vez que os discos de maior desempenho são utilizados para os dados mais recentes e os discos menos dispendiosos para o armazenamento dos dados menos utilizados. Isto conduz a uma velocidade de resposta mais rápida e a custos mais baixos. Além disso, todas as tarefas administrativas da base de dados (tais como cópias de segurança) são optimizadas porque podem ser executadas em partições individuais.
Outro ponto forte desta solução, em comparação com o armazenamento externo, é o facto de os dados permanecerem sempre em linha e não serem transferidos para qualquer dispositivo externo, o que é muito importante para garantir a uniformidade e a recuperação eficiente dos dados. Todos os dados permanecem online, apenas mudam a sua organização à medida que são movidos para diferentes discos e partições que oferecem diferentes desempenhos, dependendo da frequência com que são utilizados.
Esta solução oferece o melhor equilíbrio para resolver os problemas de desempenho e de tempo referidos no início. É também uma solução independente do sistema operativo e transparente no que diz respeito ao sistema de gestão utilizado: pode ser utilizada com qualquer base de dados sem necessidade de alterar nada das suas configurações pré-existentes, esta solução não tem impacto em todas as actividades realizadas e decisões tomadas anteriormente.
Podemos então resumir as vantagens do particionamento de tabelas da seguinte forma:
Melhoria dos tempos de resposta e do desempenho da consulta: O optimizador DB2 está ciente das partições e se a consulta precisar de pesquisar muitas linhas para obter um conjunto de resultados e o predicado (cláusula where) utilizar intervalos que tenham sido definidos, então apenas as partições que tenham linhas que satisfaçam a consulta serão pesquisadas em vez de pesquisar toda a tabela. Este procedimento é designado por “eliminação de partições” e pode reduzir significativamente o tempo de execução da consulta.
Tempos de backup melhorados: Várias actividades de manutenção, como a reorganização, podem ser efectuadas em partições individuais, o que será muito rápido em comparação com a reorganização de toda a tabela. Trabalhar com partições separadas é mais fácil e rápido, uma vez que certas operações podem ser escolhidas em espaços individuais, o que reduzirá o tempo. A redução do tempo de backup significa que os recursos do sistema estão disponíveis para as transacções dos utilizadores, em vez de serem guardados no armazenamento de backup.
Otimização da utilização dos discos: Os dados permanecem online e não há necessidade de os mover para dispositivos externos. Permite uma utilização eficiente do armazenamento através de uma organização diferente: o particionamento de tabelas ajuda-nos a utilizar melhor o armazenamento, de facto as partições antigas, que são acedidas com menos frequência, podem ser colocadas no armazenamento antigo/lento, enquanto no armazenamento mais recente e com melhor desempenho estão as informações mais utilizadas e recentes.
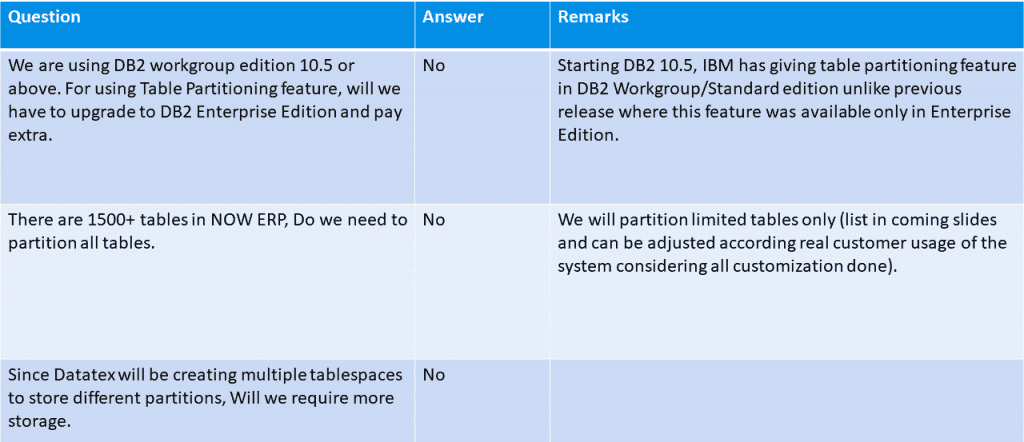
Elevado grau de flexibilidade e personalização: As tabelas podem ser personalizadas e particionadas para se adaptarem a tarefas específicas. É muito fácil ajustar os critérios de particionamento às necessidades específicas, que podem mudar ao longo do tempo. De facto, permite um processamento optimizado de roll-in ou roll-out de intervalos: novas partições podem ser rapidamente anexadas e as partições antigas podem ser rapidamente removidas, conforme necessário. Neste processo, carregar ou inserir dados numa nova partição antes de a tornar parte da tabela particionada. Este processo de carregamento não tem mais efeito na utilização da nossa tabela temática do que o carregamento de qualquer outra tabela independente na base de dados. Uma vez concluído o carregamento para a nova partição, o comando ATTACH é utilizado para integrar a nova partição na tabela de partição Range primária.
Os melhores critérios de partição serão selecionados de acordo com cada tabela e distribuição de dados: por exemplo, em StockTransaction, o critério mais adequado é o TRANSACTIONDATE ou, noutra tabela, pode ser o CREATIONDATETIME e, em ADSTORAGE, pode ser o UNIQUEID, mas também com base em dados reais, o ENTITYNAME.
A Datatex realizou testes em ambiente real de clientes para medir os potenciais benefícios da solução em termos de desempenho do utilizador final e os resultados mostram que os benefícios podem mudar de acordo com diferentes dados e diferentes formas de utilização do sistema ERP. Todos os factores influenciam o resultado e o mais importante é trabalhar em conjunto para compreender quais são as melhores partições para o desempenho.
Escrito por Roberto Mazzola – CTO da Datatex


